
Originally posted July 2019. This is a topic I’ll revisit in book 2, since teams will need to synchronize on what they mean by “good”.
Watching a design debate play out at work I’ve been struck by the lack of actual concrete feedback about the proposed alternatives. Data wouldn’t eliminate politics and personality from the conversation, but (and here perhaps I am being naive) feedback couldn’t hurt. If it’s me in the room, I’d like to hear something more concrete than, “I don’t like Adapter Factories”.
When I change the behavior of a program I can (well, I should be able to) get immediate feedback from tests about whether the behavior changed the way I expected to and only the way I expected it to. What would it mean to create an analogous minute-by-minute feedback loop for structure changes?
Good Design
A good design is one that enables needed future behavior changes. If we needed to choose between two designs, given infinite resources we would just implement them both and see which enabled needed future behavior changes.
We don’t have infinite resources, but sometimes we can play a little of this game. “You know that painful behavior change we just made? If the design was thus-and-so then that would have been a one-file change.”
One of the benefits of these hypothetical changes is concreteness. For the same reasons that the tests in test-driven development aid thinking, driving a design from a particular behavior change helps focus attention on what matters.
Hypothetical changes suffer from not being real. Maybe there’s a valid reason the hypothetical change can’t be that simple, but it won’t be obvious until after we try it.
Some Immediate Feedback?
Is it possible to offer some immediate feedback for the quality of recently completed structure changes? Maybe. Here’s an example.
Let’s say we have a duplicated snippet of code. If we change one snippet to effect a behavior change (BΔ) then we have to change the other one too.
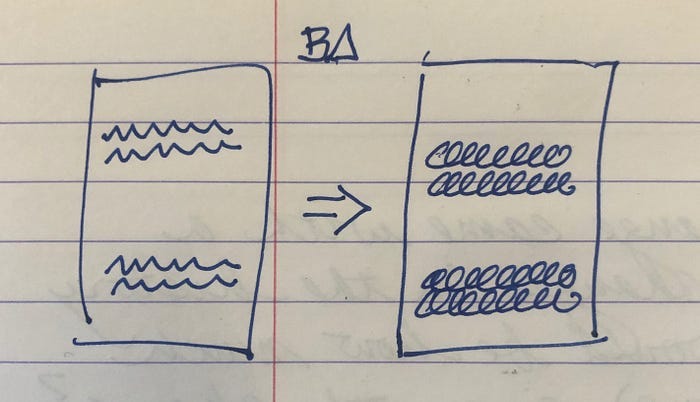
After the structure change (SΔ) of extracting a common helper method, the equivalent behavior change (BΔ’)can be made by changing the helper.
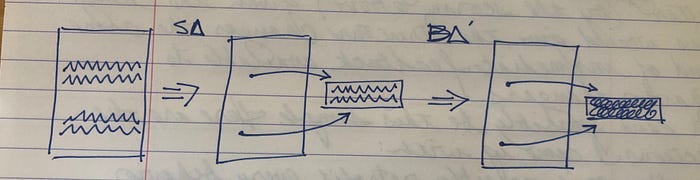
Here’s the question — given BΔ and SΔ, under what conditions can we automatically derive BΔ’? This seems to me to be intractable in general (glad to be proven wrong), but can it be done for a useful subset of changes?
Scoring Structure Changes
If we can derive what a behavior change would have been had a structure change already been applied, then we can compare the behavior change with and without the structure change. What does that scoring function look like?
Fewer places to change is better (the reduced coupling of the example above).
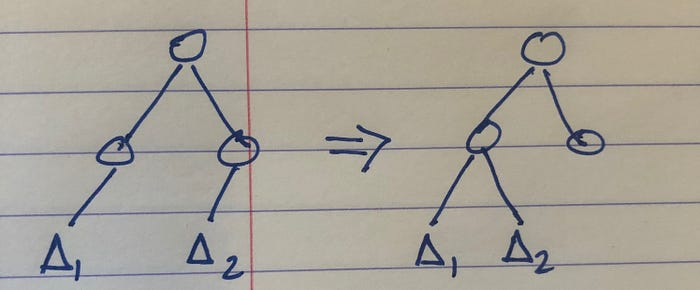
Smaller “span” of changes is better. For a system arranged hierarchically, the closer the common ancestor of the changes the better. (One flavor of cohesion)
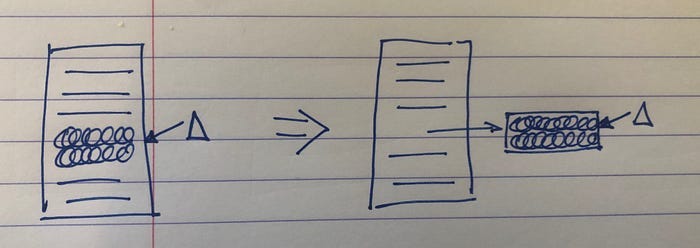
The more of an element changed the better (the other flavor of cohesion). In the example below, extracting a helper method that needs to be completely replaced is better than modifying 2 of many lines in the original method.
Testing Structure Changes
Given these two abilities — deriving equivalent behavior changes after a structure change has been applied and scoring behavior changes — we can roughly test the effectiveness of structure changes. Given a structure change, evaluate all behavior changes since ever and compare the scores before and after the structure change.
Say I extract a method. The environment responds with, “4 historical behavior changes would have improved scores based on this change.” Or, “3 changes would improve and 6 changes would score lower.” This seems like useful feedback to me.
Some of the behavior changes will fail to be applied. For some behavior changes the structure change will be irrelevant. That’s fine. I want some feedback now, not a perfect answer.
Caveats
The approach to testing structure changes outlined here has many limitations. It’s intended as a “better than nothing/arguing”, not as a final word (although the hints at ML offered by a fitness function are intriguing). Here are some of the limitations.
Post hoc. We can only score the behavior changes we have already made, not the changes we are going to make. The future tends to be similar to the past, except when it isn’t.
Hill climbing. I can imagine blocks of structure changes the early parts of which make scores worse until the last changes improve scores dramatically. Not sure if this would really happen, but it’s something to watch for.
Golf. The best design for a system isn’t necessarily the one that lowers the aggregate score of all behavior changes, not if that design limits those making behavior changes to those who built the system. “Clever” comes at a cost which may or may not be worth it.
Goodhart’s Law. The scores should inform individual decision making. As soon as you generate a number, someone lacking in confidence in their decisions will evaluate the number instead of looking at the territory.
After reading your latest book, I’ve been thinking a lot about cohesion. In quest for better understanding, I read about linguistic cohesion. Looked for antonyms for it. That lead me to the word”incoherent”.
Cohesion and coherent seem strongly related. By leveraging cohesion something becomes more coherent. It can be reasoned about more easily, more easily elaborated and more easily isolated.
Thanks for helping make the idea more understandable.
The visualizations make me think of fMRIs showing neural activity in brains during cognitive processes
https://en.m.wikipedia.org/wiki/Functional_magnetic_resonance_imaging