
First published 2016.
“I can’t get any code out with all these meetings.” What if this perennial engineer complaint has causation backwards? Adding and removing organizational overhead is relatively easy compared to increasing an organization’s capacity to deploy code. What if meetings and reviews are an organization’s adaptive response to avoid overloading deployment?
Chuck Rossi [ed: legendary release manager at early-to-middle Facebook] made the observation that there seem to be a fixed number of changes Facebook can handle in one deployment. If we want more changes, we need more deployments. This has led to a steady increase in deployment pace over the past five years, from weekly to daily to thrice daily deployments of our PHP code and from six to four to two week cycles for deploying our mobile apps. This improvement has been driven primarily by the release engineering team (I’m a fan, can you tell?)
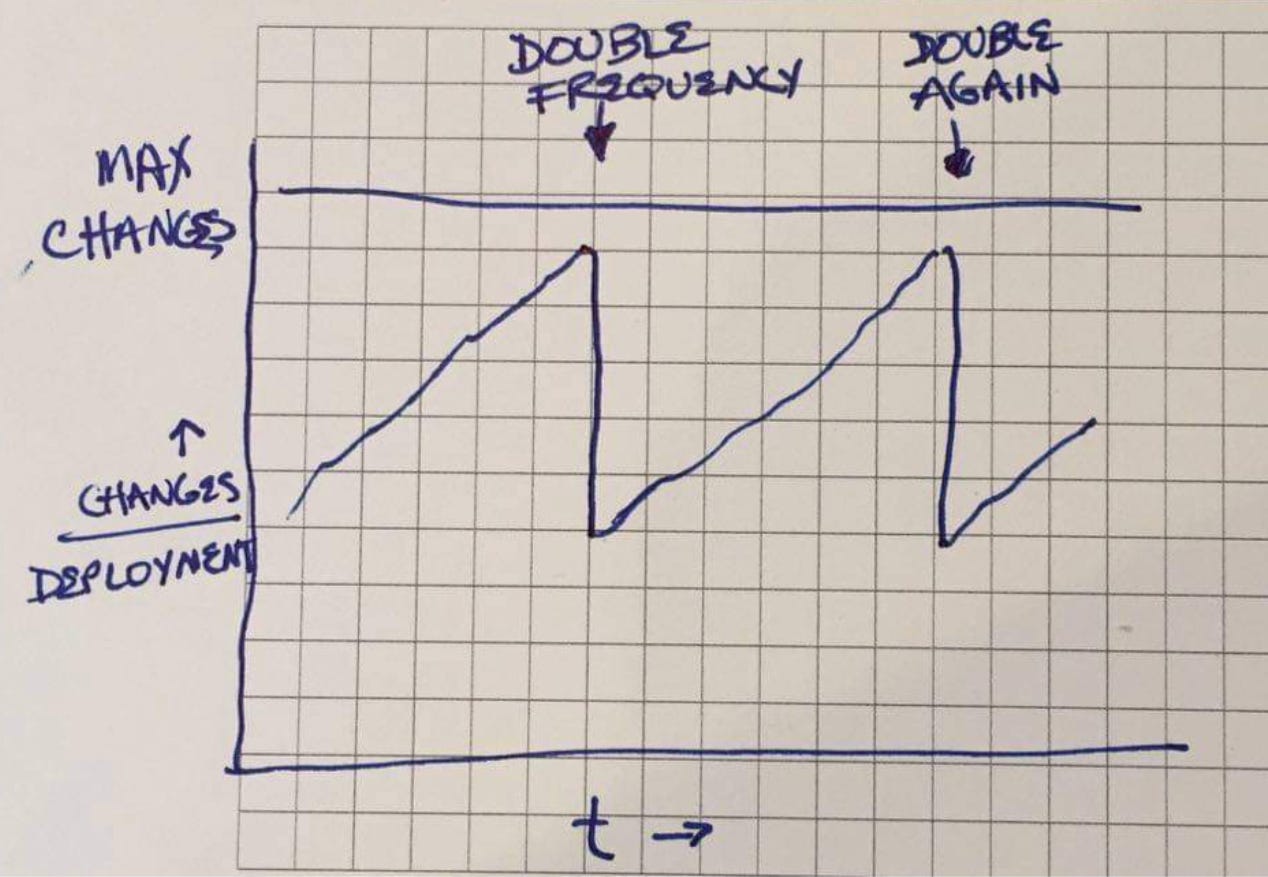
As I was drifting off to sleep yesterday, I visualized the sawtooth-shaped “changes per deployment” graph and it struck me that maybe we had organizational overhead all wrong. “Changes per deployment” seems like an inelastic metric. It’s possible to improve, but only with great effort over time. What happens when the number of changes produced exceeds the current threshold? Changes per deployment doesn’t change. The number of changes has to go down.
How? By increasing overhead—meetings, reviews, handoffs, overhead and eventually by killing enthusiasm and initiative. Nobody is going to own up to doing it on purpose, but perhaps the organization’s emergent response is locally optimal—change the thing that is easiest to change that will relieve the pressure.
Increasing overhead initiates a positive feedback loop: less getting done -> more pressure -> more mistakes -> even fewer changes per deployment -> more overhead -> less getting done. Isolated efforts to reduce overhead increase pressure and increase overhead.
If you want more changes to get through, you need to expand the far end of the hose, to increase deployment capacity. You can do this the hard way, by reducing the deployment cycle and dealing with the ensuing chaos, or the harder way, by increasing the number of changes per deployment (better tests, better monitoring, better isolation between elements, better social relationships on the team). But don’t try to reduce overhead. That’ll just lead inevitably to a series of meetings on how to reduce meetings. At least that will keep you from trying to ship too much code, though.
This essay is an example of the Thinkie Reverse Causality. It’s one of the most fun Thinkies to deploy because they ideas seem just so wrong at first.
would it be fair to say this is an expression of 'large change = large risk' and 'lots of small changes = small risk'? trying to reduce risk leads to meetings, quality gates, extra testing etc, more people wanting to be involved/informed so they can prepare for the risk thing etc.
This reminds me so much of my time at Adobe. I have never worked anywhere that had so many meetings. And if you couldn't get consensus in a small group meeting, the solution seemed to always be to add more people to the meeting. I had several hour-long meetings each week that had over a dozen people in them, some up to two dozen people. Heaven forbid, anyone made a decision on their own and actually got anything useful done!